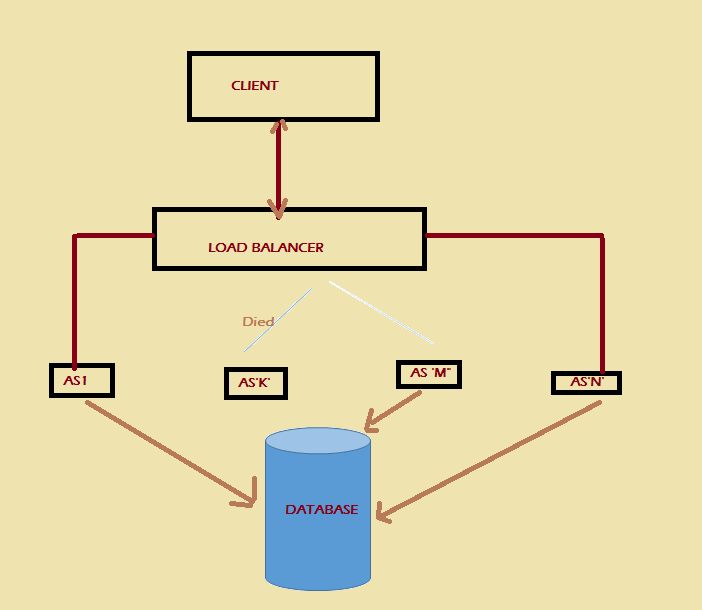
This is the continuation of URL shortening design. In this entry we will explore different expect of our proposed design.
In the proposed design, we are optimizing for consistency over availability and we agreed to choose a NoSQL database which is highly consistent like HBase or Cassandra. HBase maintains a table called metatable, that points which key is present at which machines. HBase distribute keys based on the load on machines, they called it region servers. Cassandra inherently use consistency hashing for sharding. Since total data in our case is few TBs, we don't need to think about sharding across data centers. NoSQL has single machine failure handling inbuilt. A NoSql database like HBase would have availability issue for a few seconds for the effected keys, as it tries to maintain strong consistency.
We can also use LRU caching strategy to add performance since most URL's are accessed for only a small amount of time after creation. Also, if the shortened URL goes viral, serving it through cache will reduce the chances of overloading the database. We can go with Redis or Memcached for caching.
To shard the data across databases, we can use integer encoding of the shortened URL to distribute data among our database shards. Let's we assign values from 0 to 61 to characters a to z ,A to Z and 0 to 9, we can compute the integer encoding of the shortened URL. We will use consistent hashing to ensure we do not have to rehash all data if we add a new shard in future.
To add fault tolerance, we can use a scheme called Master-slave scheme for shards, wherein one machine called master process all writes and there are slaves machines which just subscribe to all the writes and keep updating itself. In an event when the master goes down, one of the slave can take over and start responding to the write queries. The slaves are to serve read requests.
In the proposed design, we are optimizing for consistency over availability and we agreed to choose a NoSQL database which is highly consistent like HBase or Cassandra. HBase maintains a table called metatable, that points which key is present at which machines. HBase distribute keys based on the load on machines, they called it region servers. Cassandra inherently use consistency hashing for sharding. Since total data in our case is few TBs, we don't need to think about sharding across data centers. NoSQL has single machine failure handling inbuilt. A NoSql database like HBase would have availability issue for a few seconds for the effected keys, as it tries to maintain strong consistency.
We can also use LRU caching strategy to add performance since most URL's are accessed for only a small amount of time after creation. Also, if the shortened URL goes viral, serving it through cache will reduce the chances of overloading the database. We can go with Redis or Memcached for caching.
To shard the data across databases, we can use integer encoding of the shortened URL to distribute data among our database shards. Let's we assign values from 0 to 61 to characters a to z ,A to Z and 0 to 9, we can compute the integer encoding of the shortened URL. We will use consistent hashing to ensure we do not have to rehash all data if we add a new shard in future.
To add fault tolerance, we can use a scheme called Master-slave scheme for shards, wherein one machine called master process all writes and there are slaves machines which just subscribe to all the writes and keep updating itself. In an event when the master goes down, one of the slave can take over and start responding to the write queries. The slaves are to serve read requests.