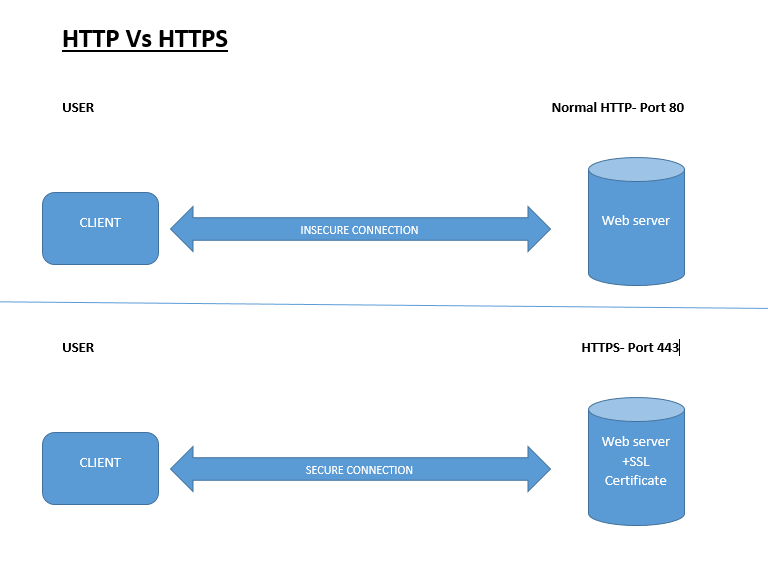
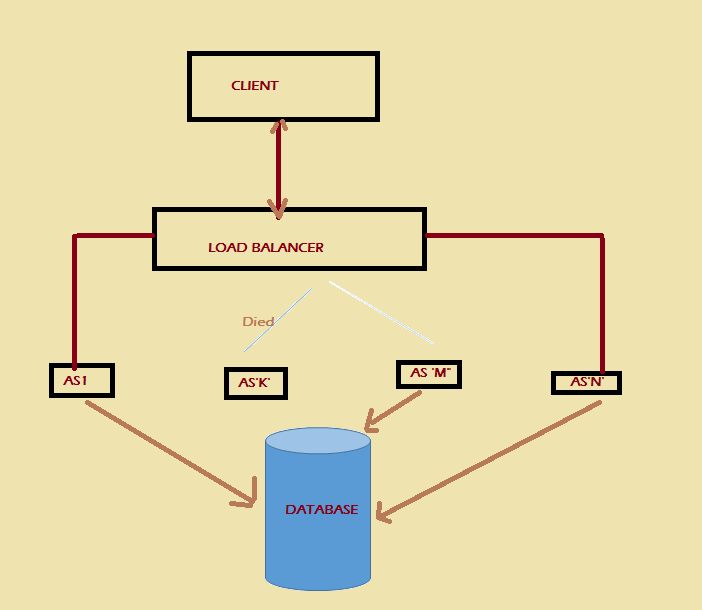
Like any other search engines, Google uses some special algorithms to generate search results. Google shares the general facts about these algorithms, but the specifics are their secret. This helps Google remain competitive with other search engines available and reduces the chance of someone finding out how to abuse the system as whole.
Google uses spider or crawlers - automated programs that crawl over millions of pages on web. Also like other search engines, Google maintains a large index of keywords and metadata like where these words can be found and linking for the same. Google uses unique algorithm(called PageRank- assigns each page a relevancy score) to rank search results, which in turn determines the order Google displays results on search result webpage.
Spider does the search engine's grunt task. It scan the web pages and creates the indexes of keywords. It also scans pages and does categorization. Once a spider has visited a web page, it follows the links from that page to other pages. It continue to crawl from one site to next, which implies the search engine's index become more comprehensive and robust with time.
The relevancy score-PageRank for a page depends on few factors:
As more pages link to Adobe's Dreamweaver page, the Adobe's PageRank increases. When Adobe's page rank is higher than the other, it shows up the top of the Google search result page. Since Google uses links to a webpage as an attribute to calculate relevancy score, its not easy to cheat the system. The genuine way to make sure your web page is high up on Google's search result is to provide great content to users so that they will link back to your page.The more links your page will gets, the higher the relevancy score will be.
Google uses lots of tricks to prevent people from cheating the system and get higher score. For example - as a Web page adds links to more sites, its voting power decreases. A Web page that has a high PageRank with lots of outgoing links can have less influence than a lower-ranked page with only one or two outgoing links.
Useful resources:
https://www.google.com/insidesearch/howsearchworks/thestory/
Google uses spider or crawlers - automated programs that crawl over millions of pages on web. Also like other search engines, Google maintains a large index of keywords and metadata like where these words can be found and linking for the same. Google uses unique algorithm(called PageRank- assigns each page a relevancy score) to rank search results, which in turn determines the order Google displays results on search result webpage.
Spider does the search engine's grunt task. It scan the web pages and creates the indexes of keywords. It also scans pages and does categorization. Once a spider has visited a web page, it follows the links from that page to other pages. It continue to crawl from one site to next, which implies the search engine's index become more comprehensive and robust with time.
The relevancy score-PageRank for a page depends on few factors:
- The frequency and location of keywords within the page.
- How long the webpage has expired.
- The number of other Webpages linked to the page in question.
lets understand it with an example where we are searching for the term "Dreaweaver".

As more pages link to Adobe's Dreamweaver page, the Adobe's PageRank increases. When Adobe's page rank is higher than the other, it shows up the top of the Google search result page. Since Google uses links to a webpage as an attribute to calculate relevancy score, its not easy to cheat the system. The genuine way to make sure your web page is high up on Google's search result is to provide great content to users so that they will link back to your page.The more links your page will gets, the higher the relevancy score will be.
Google uses lots of tricks to prevent people from cheating the system and get higher score. For example - as a Web page adds links to more sites, its voting power decreases. A Web page that has a high PageRank with lots of outgoing links can have less influence than a lower-ranked page with only one or two outgoing links.
Useful resources:
https://www.google.com/insidesearch/howsearchworks/thestory/